
Page 122 - Demo
P. 122
Chapter 7120fifi\!fifi,fffifi,fflfifi\!fififffififflfl fiffififi\!fifi,fffifi,fflfifi\!fififffififflfl#fi
% \ \ffl ! % % % %% % \% % % % ff % %% % % % \% % ! % % ! % % % % % \#ffifi fl$fi flfiffi fi
!!%fifi\!fifi,fffifi,fflfifi\!fififffififflfl fiffififi\!fifi,fffifi,fflfifi\!fififffififflfl#fiff % ! % % % % % % \! ! ffl % % \ % % % % % % % ff ffl % %% % % % \% % % % ffl % % % % % % #ffifi fl$fi ffi fiffi fi
%%%\!%%ÿ%%\ff
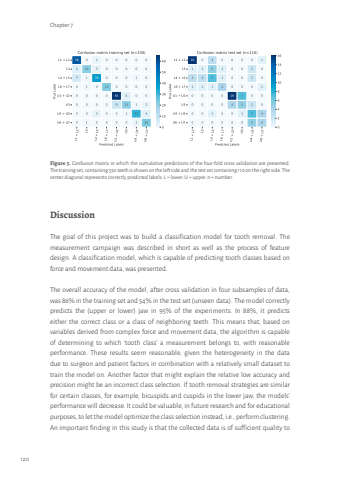
%\ffFigure 3. Confusion matrix in which the cumulative predictions of the four-fold cross validation are presented. The training set, containing 330 teeth is shown on the left side and the test set containing 110 on the right side. The center diagonal represents correctly predicted labels. L = lower. U = upper. n = number. DiscussionThe goal of this project was to build a classification model for tooth removal. The measurement campaign was described in short as well as the process of feature design. A classification model, which is capable of predicting tooth classes based on force and movement data, was presented. The overall accuracy of the model, after cross validation in four subsamples of data, was 86% in the training set and 54% in the test set (unseen data). The model correctly predicts the (upper or lower) jaw in 95% of the experiments. In 88%, it predicts either the correct class or a class of neighboring teeth. This means that, based on variables derived from complex force and movement data, the algorithm is capable of determining to which ‘tooth class’ a measurement belongs to, with reasonable performance. These results seem reasonable, given the heterogeneity in the data due to surgeon and patient factors in combination with a relatively small dataset to train the model on. Another factor that might explain the relative low accuracy and precision might be an incorrect class selection. If tooth removal strategies are similar for certain classes, for example, bicuspids and cuspids in the lower jaw, the models’ performance will decrease. It could be valuable, in future research and for educational purposes, to let the model optimize the class selection instead, i.e., perform clustering. An important finding in this study is that the collected data is of sufficient quality to Tom van Riet.indd 120 26-10-2023 11:59
